오픈AI 퇴사자의 글 #1 : 2027년 AGI가 온다
.png?type=w800)

안녕하세요 올바른입니다. 좋아요는 리서치에 힘이 됩니다 🙂
오픈AI가 얼마 전 AGI의 출현에 대비하여 안전을 다루던 초정렬팀을 해체했습니다. 그리고 뒤이어 오픈AI 초정렬팀에서 퇴사한 연구원은 AGI에 관해 165페이지에 달하는 글을 올렸습니다.
그의 말은 “샌프란시스코에서 가장 먼저 미래를 볼 수 있습니다.“로부터 시작됩니다. 2027년 AGI가 달성될 것이며 왜 달성될 것이라 생각하는지, 사람들이 간과하는 것을 짚었습니다. 2019년 유치원생 수준의 GPT-2를 지나 2023년 똑똑한 고등학생 수준의 GPT-4까지 달려온 4년에 대해 설명하고, 앞으로 AGI를 향해 달릴 4년과 그보다 더 큰 문제인 초지능을 얘기합니다.
|
AI 업계를 이해하는 자료 |
|
|
2024-02-21 |
구글 잼민이 왜케 잘해, ‘제미나이(Gemini) 1.5’ (바로가기) |
|
2024-02-20 |
오픈AI가 만든 AGI의 초석, ‘소라(Sora)’ (바로가기) |
|
2023-12-27 |
엔비디아와 생성형AI : ‘Zero to One’ 첫 해를 정리하며 (바로가기) |
|
오픈AI 인터뷰 |
|
|
2024-03-26 |
오픈AI 샘 올트먼 인터뷰 : “컴퓨팅은 세계에서 가장 귀중한 화폐가 될 것” (바로가기) |
|
2024-01-19 |
빌 게이츠, 오픈AI 샘 올트먼 인터뷰 : 40배 낮아진 GPT 비용, 지능 → 로봇 생산성 혁신 (바로가기) |
|
2024-01-12 |
|
*해당 게시물은 단순 의견 및 기록용도이고 매수매도 등 투자권유를 의미하지 않습니다.
*해당 게시물의 내용은 부정확할 수 있으며 매매에 따른 손실은 거래 당사자의 책임입니다.
*해당 게시물의 내용은 어떤 경우에도 법적 근거로 사용될 수 없습니다.
목차
-
AGI를 향해 달리는 오픈AI : Superalignment 해체 후 퇴사직원이 말하는 실체
-
오픈AI 퇴사자가 말하는 AGI : “샌프란시스코에서 가장 먼저 미래를 볼 수 있습니다”
-
1장, GPT-4에서 AGI로 가는 길 : OOMs을 계산해봅시다
-
지난 4년간의 AI 발전
-
Compute
-
Algorithmic efficiencies
-
Unhobbling
-
-
향후 4년의 발전
-

AGI를 향해 달리는 오픈AI
Superalignment 해체 후 퇴사직원이 말하는 실체
-
오픈AI 초정렬팀 해산 : 지금으로부터 한 달 전, 샘 올트먼은 오픈AI 내에서 AGI 출연에 대비하는 안전팀인 ‘초정렬(Superalignment)‘팀을 해체했습니다. 초정렬팀 자체는 GPT를 개발하고 주도했던 일리야 수츠케버(Illya Sutskever)가 2023년 7월에 만들었던 팀입니다. AI의 안전성에 중점을 뒀던 수츠케버는 상대적으로 빠른 AGI 개발을 원했던 올트먼과 잦은 충돌을 일으켰었습니다. 그 결과로 2023년 11월에 수츠케버가 이사회 동의를 얻어 긴급하게 샘 올트먼을 이사회에서 축출했던 일이 있었죠. 오픈AI 팀 전원이 올트먼의 복귀를 바라면서 올트먼이 다시 돌아왔고 수츠케버의 난은 일단락됐었습니다. 그러나 실제 그 후로 점점 초정렬팀은 전체 컴퓨팅 할당 우선순위에서 밀렸고 → 5월 18일에는 팀 해체에 이르렀습니다.

-
초정렬팀 해체 이면의 이야기 : 5월 18일 오픈AI 초정렬팀이 해체됐습니다. 이에 일리야 수츠케버와 함께 초정렬팀을 이끌었던 또 다른 임원인 얀 레이케(Jan Leike)가 퇴사소식을 밝히면서 이면의 이야기를 말해 화제였었습니다. 원문은 여기서 찾아보실 수 있는데요. 초정렬팀 해체 당시 얀 레이케가 밝힌 내용은 이렇습니다. 오픈AI 내에서 연구활동을 하려면 컴퓨팅 할당을 받아야 하는데 컴퓨팅 할당의 우선순위에서 초정렬팀이 점점 밀렸습니다. 따라서 모든 오픈AI 직원들이 AGI를 느끼고 책임감 있게 개발해주길 바란다며 글을 마무리했습니다. 그리고 그는 앤트로픽 거대모델 초정렬 연구를 이어가고 있습니다.
-
초정렬팀 해체는 폭주기관차를 의미하는가? : 초정렬팀 해체에 대해서 정답을 알 수는 없겠습니다. 다만, 단순한 폭주기관차 가능성 이상을 생각해볼 수는 있습니다. AI 안전을 연구하는데 있어서 새로운 방법론이 추진력을 얻고 있었기 때문입니다. 2023년 10월에 GPT-4V를 보고 향후 모든 모델이 멀티모달화 될 것임을 생각했던 것처럼, 이제는 앞으로 신경망 해석이 많은 부분을 바꿀 것이라 생각합니다.
-
딥러닝의 치명적인 한계 ‘블랙박스’ : 우선 딥러닝은 기존 머신러닝 모델들에 비해서 더 높은 성능을 보이고, 이전에 풀지 못했던 사례를 푸는 등 효과적인 학습방법이었습니다. 그러나 치명적인 단점이 있습니다. 모델의 의사결정을 알 수 없는 블랙박스(Blackbox) 현상입니다. 어느 정도 이상 결과가 좋을 때는 블랙박스 여부가 크게 상관있지 않았습니다. 테슬라 FSD가 걸어온 길처럼 훈련할 때마다 다양한 버전을 나눠두고 각각 새로운 데이터를 넣어 가중치를 바꿔가며 훈련시킨 뒤 성능이 가장 좋은 모델의 안전성 평가를 해보고 → 내부 직원 → 100명 테스터 → 1,000명 테스터 → 초기 배포 → 완전 배포식으로 업데이트해왔던 길이기도 합니다.
-
LLM의 가능성을 확인한 GPT-3 : 그러나 LLM으로 할 수 있는 일이 많아진 시대입니다. 요구하는 능력이 달라졌습니다. 이제 로보택시가 필요하고, AI 판사, AI 비서, AI 변호사, AI 세무사를 필요로 하는 시대가 왔습니다. 그리고 무엇보다 이젠 해볼 수 있을 거 같다는 인식이 생겼습니다. 단위 컴퓨팅당 비용이 기하급수적으로 낮아졌기 때문입니다. 더 많은 컴퓨팅을 쓸 수 있게 되자 해볼만한 비용으로 LLM을 만들 수 있게 됐고 오픈AI의 2020년 1월 논문 <Scaling Laws for Neural Language Models>가 LLM의 가능성을 확인했고 → 그 후 2020년 6월에 발표된 GPT-3가 시작을 알렸습니다. 이에 대해서는 이전 자료인 <오픈AI가 만든 AGI의 초석, ‘소라(Sora)’>를 통해 설명해드렸습니다.
-
해석가능한 인공지능모델에 대한 열망 : AI 연구소들의 주 컴퓨팅 할당은 딥러닝 성능향상을 위한 연구에 있습니다. 어떻게 하면 각 기능마다 더 높은 성과를 낼 것인지, 어떻게 하면 더 효율적으로 훈련시킬 것인지, 어떻게 하면 추론능력을 더 높일 것인지 등을 다루는 일입니다. 그러나 한 켠에서 AI 모델의 안전과 정렬에 관련된 연구를 하는 팀은 ‘모델이 의사결정을 내리는 과정을 설명가능한 모델’, 즉 해석가능한 인공지능모델(Explainable AI, “XAI”) 연구를 해왔습니다. 그리고 이제 AI 안전을 연구하는데 있어서 새로운 방법론이 하나씩 메인 연구과제로 떠오르기 시작했습니다.
-
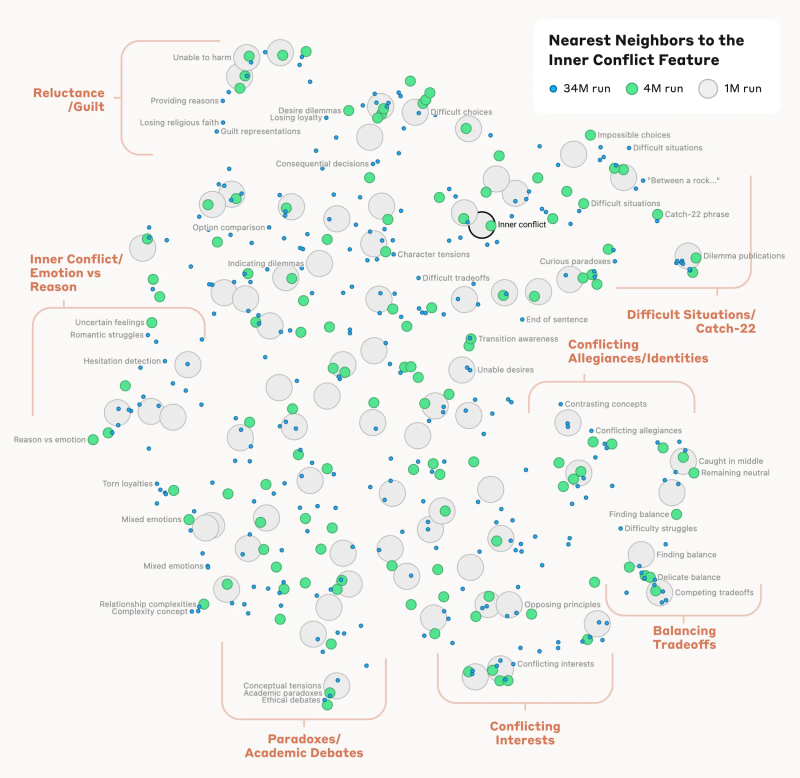
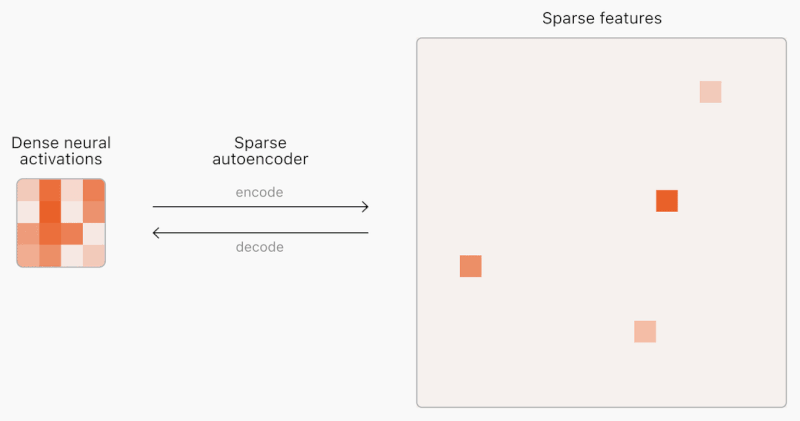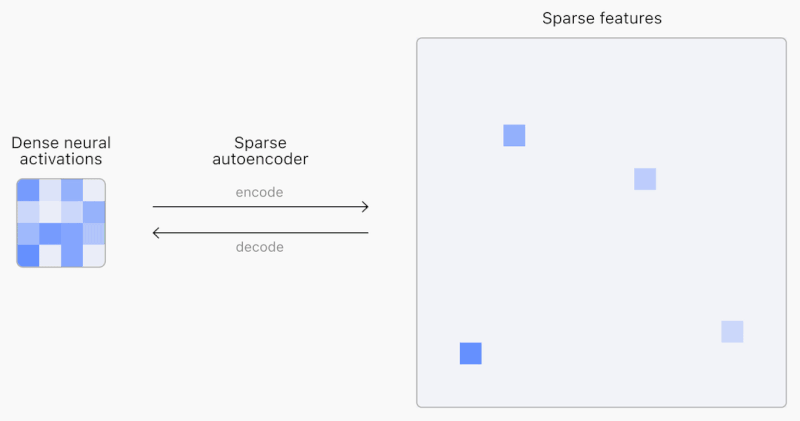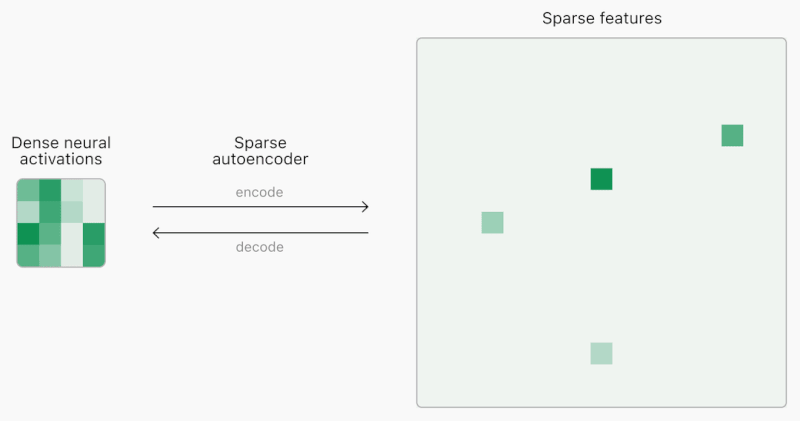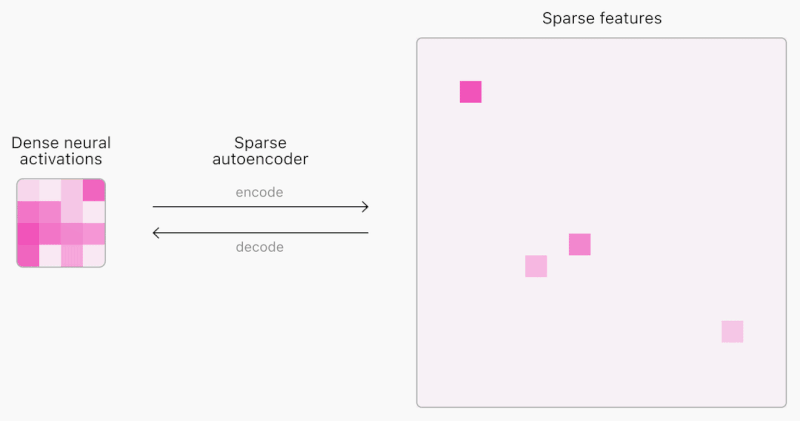
*코멘트 → 왼쪽은 앤트로픽의 Mapping the Mind of LLM을 다룬 내용이고, 오른쪽은 오픈AI의 Extracting Concepts from GPT-4에서 발표된 Sparse autoencoder 모습입니다. 간단하게 보자면 세계에서 가장 뛰어난 파운데이션 모델 개발기관 두 곳이 거의 동시에 해석가능한 AI 모델의 가능성을 열었습니다.
-
‘XAI’ 가능성이 보이기 시작 : 앤트로픽(Anthropic)이 5월 21일 <Mapping the Mind of a Large Language Model>를 통해서 업계 최초로 LLM 내의 블랙박스를 일부 해석할 수 있는 연구를 공개했습니다. 미국에 있는 유명한 다리인 금문교(Golden Gate Bridge)에 해당하는 텍스트나 이미지로 인해서 활성화되는 신경망들의 패턴을 찾는 연구였습니다. 재미있는 건 인간의 기억 속에 특정 기억을 키울 수 있다면 왜곡을 일으키는 것처럼, 연구 대상 LLM이었던 클로드 3 소넷(Sonnet)도 금문교 Feature를 증폭시키니 왜곡을 일으키더라는 것입니다. 예를 들어 금문교에 대한 Feature를 증폭시킨 후 “당신의 신체적인 형태는 어떻습니까?“라고 물으니 평소라면 ⓐ “저는 AI모델이므로 신체적인 형태가 없습니다.“라고 답했지만, 이번에는 ⓑ “저는 금문교입니다… 제 모습은 상징적인 다리 형태 그자체입니다…“라며 답했다는 것입니다. 인간의 기억에 왜곡이 생긴 현상과 비슷하게 LLM이 금문교에 집착하는 모습을 보이더라는 것이죠. 이 과정을 통해 특정 Feautre를 조작할 시 인과관계를 알 수 있습니다. 이를 통해 코드 백도어를 막고 누군가 핵무기 제작방법을 묻는다거나, LLM이 성차별이나 범죄적인 답변을 하지 않도록 하거나, AI가 인간을 전복시킬 우려를 최대한 관리할 수 있게 됩니다.
-
비슷한 시기에 오픈AI도 새로운 XAI 논문 공개 : 그리고 얼마 지나지 않아 6월 6일, 오픈AI가 <Extracting Concepts from GPT-4>를 발표했습니다. 핵심은 마찬가지로 어떤 출력물이 나올 때 어떤 Feature가 활성화되는지를 알아내는 것입니다. 이를 찾아낸 수만큼 더 자세하게 GPT-4에서 일어나는 일을 설명할 수 있습니다. 오픈AI가 발표한 것은 기존의 Feature를 해석하는 해석기(Sparse autoencoder)와 달리 거대모델에 맞게끔 해석기의 크기도 키울 수 있는 방법에 대한 연구상황(Large scale autoencoder training)을 공개한 것입니다. 오픈AI는 잠재적으로 이 방법이 모델의 신뢰성을 높이고 관리 가능한 AI로 향해 가는 길이라 강조하지만, 여전히 현재 찾은 1,600만개의 Feature에 비해 프론티어 LLM을 완벽하게 설명하려면 수십억 혹은 수조 개의 Feature까지 확장해야 할 것이라 전망했습니다.
-
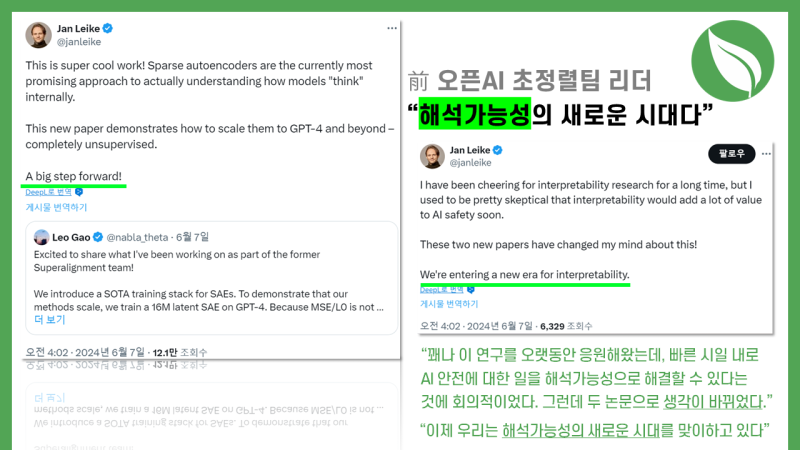
-
前 오픈AI 초정렬팀 리더 “해석가능성의 새로운 시대가 열렸다” : 아직 해결해야 할 분야는 많지만 초정렬이 하는 일도 AI를 통해 해결할 수 있는 가능성이 열리는 방향이기에 긍정적이었습니다. 오픈AI 연구 발표 당시오픈AI 초정렬팀 내 리더격(오픈AI 초정렬팀 공동책임자)이었던 임원 얀 레이케(Jan Leike)의 발언이 흥미로웠는데요. 초정렬팀 내에서도 해석가능성(Interpretability)에 대한 연구는 LLM 규모만큼 확장하기 어렵다는 생각이 있어서 회의적인 시각이 많았지만, 최근 앤트로픽과 오픈AI가 내놓은 두 연구결과를 보니 생각이 바뀌었음을 밝혔기 때문입니다. 따라서 개인적으로는 단순히 브레이크를 무력화시킨 폭주기관차의 모습보다는 AI를 정렬시키고 추론능력을 향상시키는 일도 AI한테 맡길 수 있는 시대가 올 가능성도 최근 생각하고 있습니다.
오픈AI 퇴사자가 말하는 AGI
“샌프란시스코에서 가장 먼저 미래를 볼 수 있습니다”

-
어느 날, 165페이지 분량의 PDF가 올라왔다 : 오픈AI의 초정렬팀과 관련된 이야기를 미리 다룬 이유는, 지금부터 말씀드리고자 하는 오픈AI 초정렬팀에서 퇴사한 레오폴드 아센브레너(Leopold Aschenbrenner)의 <상황인지: 앞으로 10년 Situational Awareness: The Decade Ahead>을 소개드리고 싶었기 때문입니다. 투자자에게는 어찌보면 너무 극단적인 시나리오이기에 잘 맞지 않는 글이라 생각했지만 여러 문제들을 다루고 있는 만큼 배울거리가 많았습니다. 오픈AI 내 AGI의 안전을 위해 설립됐던 부서에서 느낀 것들, 왜 초정렬팀의 수장이자 공동창업자였던 일리야 수츠케버가 AI 개발을 가속화하려는 샘 올트먼을 제지하려 했는가 등 여러 가지를 살펴볼 수 있었던 자료였습니다.
-
길지만 충분히 읽어볼 만한 자료 : 전체적으로 읽어봤을 때 길지만 충분히 읽어볼 만한 자료였습니다. 아센브레너의 글은 5개의 챕터로 구성되어 있습니다. 양이 방대하기 때문에 시간을 두고 총 세 편에 나눠서 정리할 예정입니다. 1편은 AGI로 향하는 길 → 2편은 AGI를 넘은 초지능의 길과 도전과제 → 3편은 이를 다루는 방법을 생각해보는 자료입니다. 전체 목차는 이렇습니다.
I. GPT-4에서 AGI로 향하는 길: 2027년까지의 OOM From GPT-4 to AGI: Counting the OOMs
II. AGI에서 초지능까지: 지능의 폭발 From AGI to Superintelligence: the Intelligence Explosion
III. 도전과제 The Challenges
-
-
IIIa. 수조 달러 규모의 클러스터를 향한 질주 Racing to the Trillion-Dollar Cluster
-
IIIb. 실험실 폐쇄: AGI를 위한 보안 Lock Down the Labs: Security for AGI
-
IIIc. 초정렬 Superalignment
-
IIId. 자유세계는 반드시 승리해야 합니다 The Free World Must Prevail
-
IV. 프로젝트 The Project
V. 글을 마치며 Parting Thoughts

SITUATIONAL AWARENESS: The Decade Ahead
레오폴드 아센브레너 (Leopold Aschenbrenner)
샌프란시스코에서 가장 먼저 미래를 볼 수 있습니다.
You can see the future first in San Francisco.
지난 1년 동안 화제의 중심은 $10B 규모의 컴퓨팅 클러스터에서 $100B 규모 클러스터, $1T 규모의 클러스터로 옮겨왔습니다. 6개월마다 오픈AI 이사회의 계획에는 0이 추가되고 있었습니다. 그리고 그 이면에서는 앞으로 10년 동안 조달가능한 모든 전력 계약, 조달 가능한 모든 변압기를 확보하기 위한 치열한 경쟁이 벌어지고 있습니다. 미국의 빅테크들은 전례가 없었던 힘에 수조 달러를 퍼부를 준비를 하고 있었습니다. 앞으로 10년간 미국의 전력 소비량은 수십 퍼센트 증가할 것이며, 펜실베니아의 셰일 유전에서부터 네바다의 태양광 발전소에 이르기까지 수억 개의 GPU가 윙윙거릴 것입니다.
AGI를 향한 경쟁이 시작됐습니다. 우리는 생각하고 추론할 수 있는 기계를 만들고 있습니다. 2025/26년이 되면 이 기계들은 대학을 졸업한 많은 이들의 수준을 능가할 것입니다. 10년 후에는 여러분이나 저보다 더 똑똑해질 것이며, 진정한 의미의 초지능(Superintelligence)을 갖게 될 겁니다. 그 과정에서 반세기 동안 볼 수 없었던 국가안보력이 발휘될 것입니다. 각종 프로젝트들이 시작될 겁니다. 운이 좋으면 중국 공산당과 AI 경쟁을 벌일 것이고, 운이 나쁘면 전면전을 벌이게 될 겁니다.
모두가 AI에 대해 얘기하고 있지만, 곧 다가올 미래에 대해서는 조금이라도 예견하고 있는 사람이 거의 없습니다. 엔비디아 애널리스트들은 매출성장의 정점이 2024년일 거라고 보고 있습니다. AI 업계의 주류 전문가들은 “현재 AI는 그저 다음 단어를 예측하는 것일 뿐이야“라고 의도적으로 무시하고 있습니다. 그들은 가장 발전된 AI를 보지 못했습니다. 인터넷 플랫폼 위에서 퍼진 새로운 기술 변화로 생각할 뿐입니다. 인터넷엔 과대광고와 일상적인 AI만 있기 때문입니다.
머지않아 세상이 깨어날 것입니다. 하지만 지금은 샌프란시스코와 AI 연구소에서 지금 상황(이 트렌드 대로라면 10년 내 AGI가 세상을 잡아먹을 것이라는 생각)에 대해 인식한 수백 명의 사람들이 있는 정도입니다. 어떤 기이한 운명의 힘인지는 모르겠지만 저는 그들 중 한 명입니다. 몇 년 전만 해도 이들은 미쳤다는 조롱을 받았습니다. 그러나 트렌드라인을 그려보며 이를 믿은 결과, 지난 몇 년간의 AI 발전은 정확하게 예측과 일치했습니다. 향후 몇 년 동안의 전망도 맞을지는 아직 미지수입니다. 하지만 이들은 제가 만난 사람 중 가장 똑똑한 사람들이었고, 이 기술을 일선에서 직접 구축하고 있는 사람들이었습니다. 아마도 그들은 역사에서 특이했던 사람들이라 기록될 수도 있고, 실라드나 오펜하이머, 텔러처럼 역사에 기록될 수도 있습니다. 만약 그들이 미래를 조금이라도 정확하게 예측하고 있다면, 우리는 곧 엄청난 변화를 겪을 겁니다.
현재 상황을 말씀드리겠습니다.
Let me tell you what we see.
GPT-4에서 AGI로 가는 길
OOMs을 계산해봅시다

2027년 AGI가 출현하는 건 놀라울 정도로 그럴듯한 시나리오입니다(AGI by 2027 is strikingly plausible). GPT-2에서 GPT-4로 오면서 4년 만에 미취학 아동은 똑똑한 고등학생 수준의 능력까지 올라왔습니다. 컴퓨팅과 알고리즘 효율성의 트렌드를 따라가고 있습니다. 0.5 orders of magnitude 만큼을 연간 OOMs으로 보겠습니다. 그렇게 본다면 2027년까지 우리는 지금까지 겪었던 것처럼 다시 한 번 지금의 가장 발전한 AI가 유치원생이고 → 27년 뒤에 나올 새로운 모델이 고등학생이 되는 정도의 질적 도약을 경험할 수 있습니다.
“보세요. 저 모델들은 그저 배우고 싶을 뿐입니다. 그 점을 이해해야 합니다. 모델들은 그저 배우고 싶어할 뿐이에요.”
Look. The models, they just want to learn. You have to understand this. The models, they just want to learn.
일리야 수츠케버 (2015년 발언)
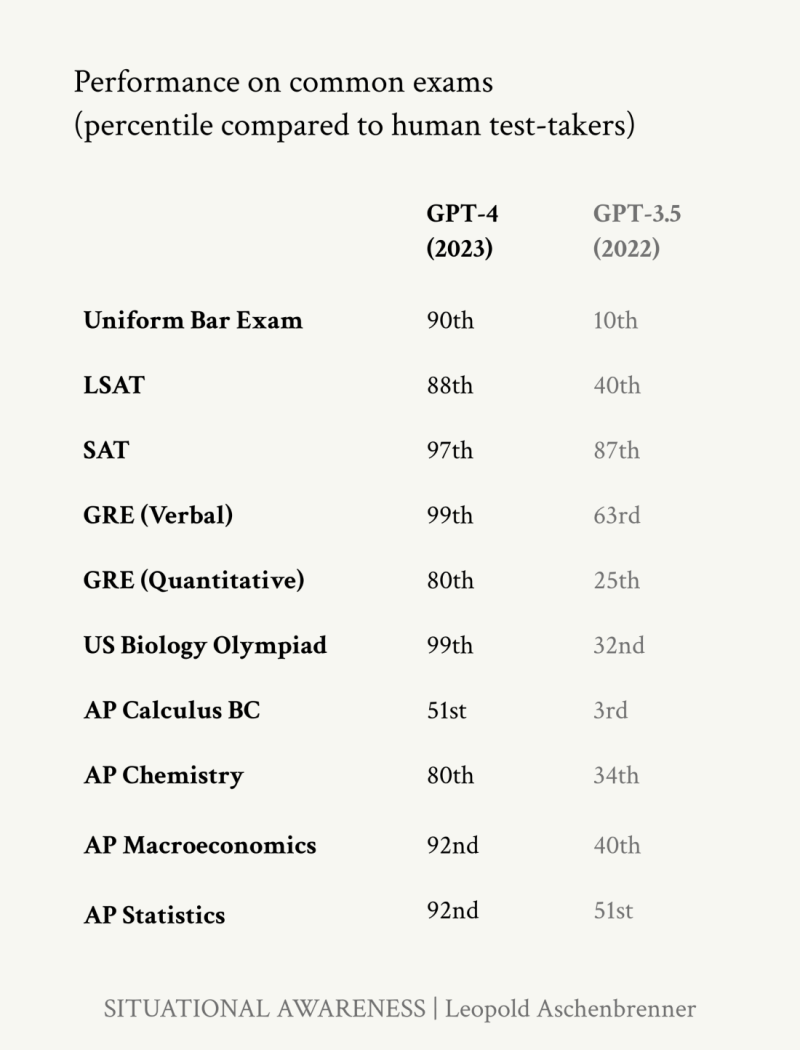
GPT-4의 능력은 많은 이들에게 충격을 안겼습니다. 코드를 쓰고 에세이를 작성하며, 어려운 수학문제를 풀 수 있고, 대학 시험에서도 우수한 성적을 받은 AI 시스템이었기 때문입니다. 몇 년 전만 해도 대부분의 사람들은 이 벽을 뚫을 수 없을 거라 생각했습니다.
그러나 GPT-4는 지난 10년간의 딥러닝 업계에서 일어난 비약적인 발전의 연장선상에 있는 모델일 뿐이었습니다. 10년 전에는 모델이 고양이와 강아지 정도의 단순한 이미지를 겨우 식별했고, 4년 전에는 GPT-2가 그럴듯한 문장을 겨우 연결하는 수준이었습니다. 이제 우리는 우리가 생각할 수 있는 벤치마크들을 모조리 능가하고 있습니다. 그러나 이러한 극적인 발전은 딥러닝의 스케일을 꾸준히 확장시켜온 결과일 뿐입니다.
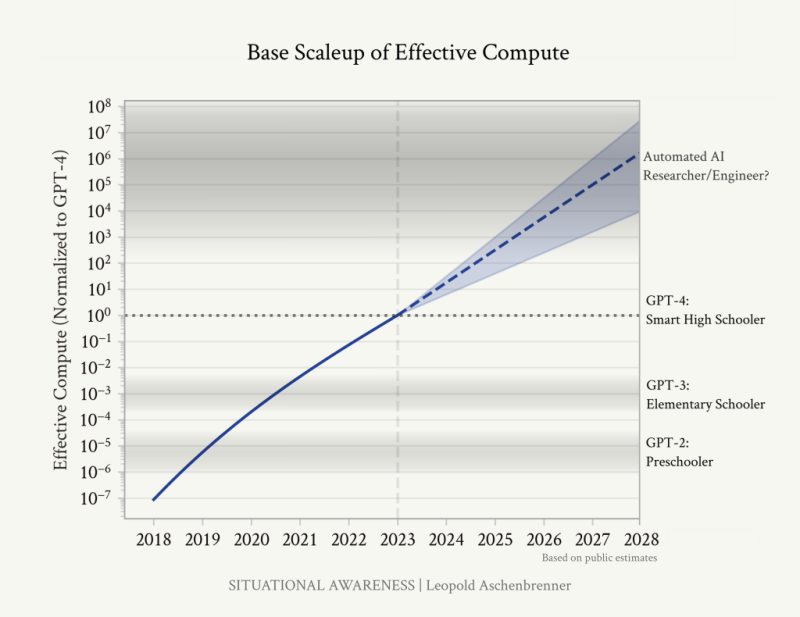
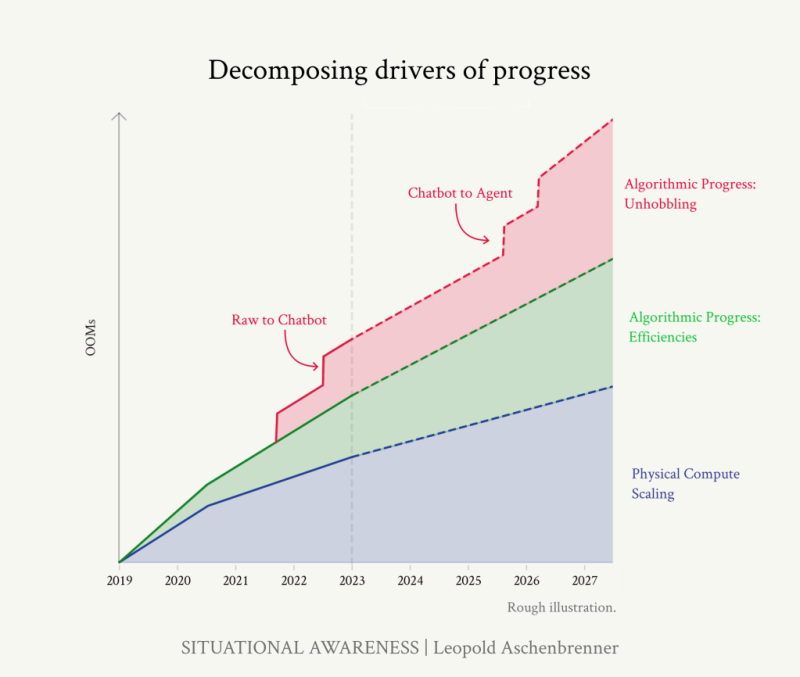
*코멘트 → 공개된 추정치를 기반으로 한 유효 컴퓨팅(물리적인 컴퓨팅과 알고리즘의 효율성을 모두 등가해서 생각한 값)은 모두 과거와 미래에 대한 대략적인 추정치입니다. 모델을 확장함에 따라 모델은 계속해서 더 똑똑해지며, OOMs를 계산함으로써 가까운 미래에 어떤 모델 지능이 나올지를 파악할 수 있습니다.
이 글에서는 지능의 발전을 “OOMs(Order of Magnitude, 10배 = 1 OOMs)로 계산”해볼 것입니다. OOMs을 결정하는 요소는 1) 컴퓨팅(Compute) 2) 알고리즘 효율성(Algorithmic Efficiencies) 3) ‘언호블링’(Unhobbling, 제기능을 못하던 부분을 개선해서 좋아지는 것)을 개선하는 것입니다. 위 차트는 GPT-4 이전 4년의 성장, 그리고 GPT-4 이후 4년 즉 2027년 말까지의 성장 기대값을 추정한 차트입니다. 딥러닝의 모든 유효컴퓨팅 OOM이 증가하는 것을 생각해보면 이런 예상이 가능합니다.
공개적으로는 GPT-4 출시 이후 1년 동안 차세대 모델이 출시되지 않았으니 딥러닝 트렌드에 문제가 생겼고 성장이 벽에 부딪혔다고 말하는 사람들도 있습니다. 하지만 직접 OOM을 계산해보셨다면 우리가 실제로 무엇을 기대할 수 있는지 알 수 있습니다.
결론은 매우 간단합니다. 일관성 있는 문장을 몇 개 조합하던 것으로 축하받던 GPT-2 모델에서, 고등학교 시험을 통과한 GPT-4 모델에 이르기까지 오면서 보인 성과들은 모두 일회성이 아닌 지속적인 진보라는 점입니다. 우리는 매우 빠르게 OOM을 통과하고 있으며 이 수치대로라면 4년 동안 약 10만배에 달하는 컴퓨팅 스케일업이 있을 겁니다. 즉 GPT-2 → GPT-4로 왔던 수준의 지능 도약이 한 번 더 이뤄진다는 것입니다. 더 중요한 건 단순히 더 나은 챗봇을 만드는 데 그치는 것이 아니라, 도구로만 쓰이던 모델수준을 벗어나 근로자를 대체할 수 있을 수준으로 가기 위한 수많은 실수들을 골라내며 간다는 점입니다.
생각 자체는 단순하지만 속뜻은 놀라운 것입니다. 이런 도약으로 이제 우리는 박사학위자나 전문가 수준의 똑똑한 모델을 동료처럼 비서로 쓰는 AGI에 도달할 수 있기 때문입니다. 가장 중요한 건 AI 시스템이 AI를 연구할 수 있도록 자동화시킬 수 있다면, 다음 챕터의 가장 중요한 주제인 강력한 피드백 루프가 시작될 수 있다는 것입니다.
지금도 이 모든 상황을 고려한 가격을 책정하는 사람은 거의 없습니다. 하지만 한 발 물러서서 트렌드를 쭉 살펴보신다면 AI에 대한 상황인식은 그리 어렵지 않습니다. 지금까지는 AI 기능에 대해서 계속 놀라셨었다면, 앞으로는 OOM을 세어보세요.
지난 4년간의 AI 발전
The last four years
이제 우리는 기본적으로 인간처럼 대화할 수 있는 기계를 갖게 됐습니다. 놀랍지 않다는 건, 이는 인간의 적응능력이 놀라울 정도로 뛰어나다는 증거입니다. 우리가 발전의 속도 자체에 벌써 익숙해졌다는 증거이기도 합니다. 하지만 한 걸음 물러서서 지난 몇 년간의 발전과정을 살펴볼 필요가 있습니다.
GPT-2에서 GPT-4로
GPT-2 to GPT-4
GPT-4까지 불과 4년(!) 만에 얼마나 많은 발전을 이뤘는지 상기시켜드리겠습니다.

*코멘트 → 당시 사람들이 GPT-2 사용사례 중 인상적이었다고 평가한 몇 가지 사례입니다. 왼쪽에서는 문장 속에서 It이 뭘 말하는지를 판단하는 아주 기본적인 독해력 문제를 풀었고, 오른쪽에서는 GPT-2가 남북전쟁에 대한 어느 정도 관련성 있는 문장을 약간 일관성 있는 수준으로 써낸 것이었습니다.
-
GPT-2 (2019년) 미취학 아동 수준 : 얀데스 산맥의 유니콘 이야기를 말했지만 사람들은 “와, 그럴듯한 문장을 몇 개 엮어낼 수 있네요.”라고 말했습니다. 당시로서는 놀라울 정도로 인상적이었습니다. 하지만 GPT-2는 겨우 숫자 5를 벗어나면 제대로 셀 수 없었고, 기사를 요약할 때는 사람이 무작위로 세 문장을 고르는 정도 수준보다도 겨우 나은 성능이었습니다. 요점을 파악하지 못했습니다.
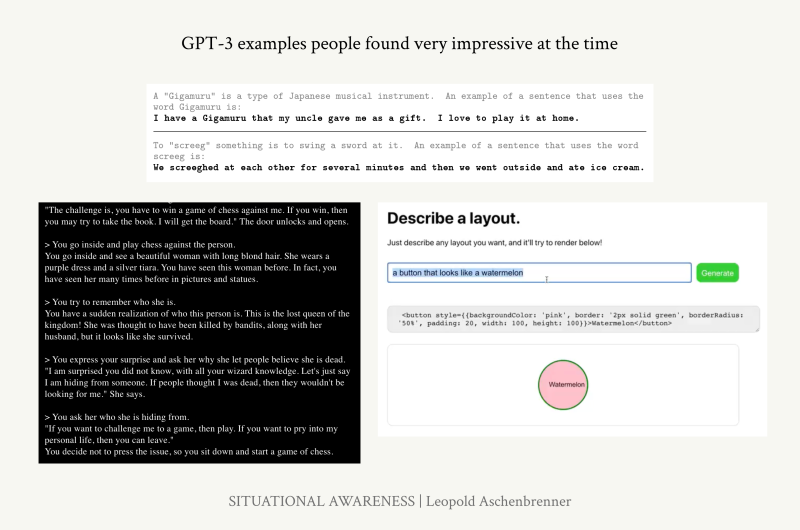
*코멘트 → 당시 사람들이 GPT-3에 대해 인상적이라고 말했던 예시 몇 가지입니다. 맨 위는 특정 단어를 알려주고 그 문장에 맞는 새로운 문장을 만들어보라는 사용사례입니다. 왼쪽 아래는 GPT-3로 스토리텔링을 할 수 있다는 것이었고, 오른쪽 아래는 GPT-3로 매우 간단한 수준의 코드를 쓸 수 있다는 것이었습니다.
-
GPT-3 (2020년) 초등학생 수준 : 사람들은 GPT-3를 보며 “와, 이제 몇 개의 예시만 주더라도 간단한 작업들을 수행할 수 있을 수준이네요.”라고 말했습니다. 여러 단락을 넘나들며 문장을 더 일관성 있게 구사할 수 있었고, 문법을 교정할 수 있을 수준이었으며 기본적인 산술도 할 수 있었습니다. 아주 좁은 의미에서 상업적으로도 쓸 수 있을 수준이 되기 시작한 때입니다. GPT-3는 검색엔진에 잘 걸리기 위한 최적화(SEO) 혹은 마케팅용 간단한 문장의 카피를 써낼 수준이 됐습니다.

*코멘트 → GPT-4가 출시됐을 때 사람들은 위쪽의 사진처럼 매우 복잡한 코드를 작성할 수 있음에 놀랐고, 왼쪽 아래처럼 수학경시문제 시험 수준의 문제를 풀 수 있었으며, 오른쪽 아래처럼 상당히 복잡한 코딩을 ‘해결’할 수 있는 수준이 됐다는 점에 놀랐습니다.
-
GPT-4 (2023년) 똑똑한 고등학생 수준 : 이제 GPT-4는 꽤 정교한 코드를 작성할 수 있었고 반복적으로 디버깅할 수 있었으며, 정교하게 글을 쓸 수 있고, 어려운 고등학교 수학경시대회 수준의 문제를 풀 수 있었습니다. 어떠한 테스트를 해도 대부분의 고등학생을 능가하는 수준이 된 것입니다. GPT-4 수준이 되자 코드 작성부터 에세이 쓰기, 초안 수정 등 일상 업무에 유용하게 쓸 수 있는 모델이 됐습니다. GPT-4라고 해서 뛰어난 수준은 아닙니다. 이러한 한계는 모델 자체의 한계라고 생각합니다.
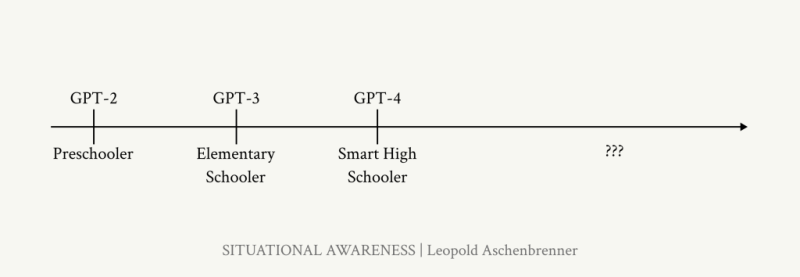
*코멘트 → 이것이 4년 동안 벌어진 일입니다. 우리는 현재 어디에 있나요?
딥러닝 트렌드
The trends in deep learning
지난 10년간 딥러닝의 발전 속도는 놀라울 정도로 빨랐습니다. 불과 10년 전만 해도 딥러닝 시스템이 단순한 이미지를 식별하는 것조차 혁명적인 일이었으니 말입니다. 우리는 계속해서 새롭고 더 어려운 벤치마크를 개발하고 있지만, 새로운 벤치마크가 나올 때마다 딥러닝은 이를 돌파하고 있습니다. 이전에는 벤치마크를 깨는데 수십 년이 걸렸지만 이제는 불과 몇 달이면 가능합니다.
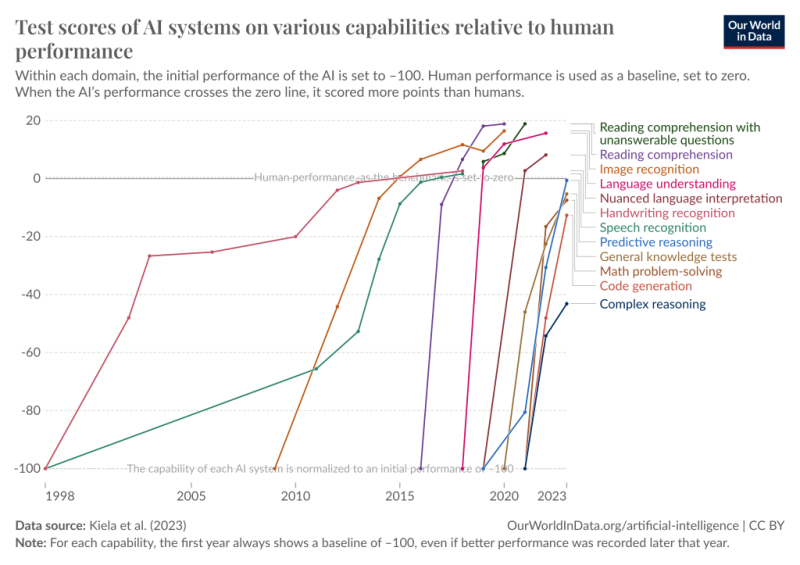
*딥러닝 기반의 AI 시스템들은 이미 많은 영역에서 인간수준에 도달했거나 뛰어넘고 있습니다.
말 그대로 이제는 벤치마크가 부족합니다. 일화로 몇 년 전인 2020년 제 친구 댄과 콜린이 ‘MMLU’라는 벤치마크를 만들었습니다. 그들은 당시에 고등학생과 대학생의 가장 어려운 시험 수준에 맞먹는, 오랫동안 유지될 벤치마크를 만들고 싶어했습니다. 그러나 3년 후 이제 프론티어 LLM은 이 문제를 넘고 있습니다. GPT-4와 Gemini는 90%의 문제를 풀고 있기 때문입니다. 더 넓게 보자면 GPT-4는 모든 표준 고등학교/대학교 적성검사를 통과하는 수준입니다. 심지어 GPT-3.5에서 GPT-4로 넘어가는 1년 사이에도 사람들 평균 이하의 성적을 받다가 최상위권으로 올라가는 경우들이 많았습니다.
2021년 고등학교 수학대회 수준의 어려운 문제인 MATH 벤치마크가 출시됐었습니다. 당시 최고의 모델은 5%의 문제를 풀었습니다. 당시 논문에서는 AI 모델이 이정도 속도로 확장된다면 비용과 효율을 생각할 때 실용적이지 않다고 주장했었습니다. 이 문제를 풀기 위해서는 새로운 알고리즘이 나와야 할 거라고 주장했었습니다. 당시 머신러닝 연구원들이 말했던 것입니다. 그러나 2022년, 1년 만에 최고의 모델은 50%를 풀었으며 지금 모델은 90% 이상을 풀고 있습니다.
매년 회의론자들은 “딥러닝은 A를 수행할 수 없습니다.”라고 주장해왔습니다. 그러나 얼마 지나지 않아 그 주장들은 틀리다는 게 입증되어 왔습니다. 지난 10년 동안 AI를 통해 배운 교훈이 있다면 딥러닝이 어디까지 발전할지에 대해서 절대 베팅해서는 안 된다는 것입니다.
현재 가장 풀기 어려운 벤치마크는 박사 수준의 생물학, 화학, 물리학 문제로 구성된 GPQA 테스트입니다. 문제를 보면 사람도 잘 이해하기 어렵게 쓰여졌습니다. 타 전공 박사들이 30분 이상 구글링한다 해도 50% 이상을 맞기가 어렵습니다. 현재 클로드 3 오푸스(Claude 3 Opus, 앤트로픽 모델 중 가장 성능이 좋은 모델)를 쓰면 60% 이상을 맞고, 각 현업에 종사하는 박사들은 80%를 받는 상태입니다. 이 기준도 1~2세대를 거치면 돌파할 것이라 생각합니다.
OOMs를 계산해봅시다
Counting the OOMs
어떻게 이런 일이 일어났을까요? 딥러닝의 마법은 아직도 통하고 있습니다. 매번 안 될 거라 바라보는 사람들이 있었음에도 추세선은 놀라울 정도로 일관되게 유지되고 있습니다.
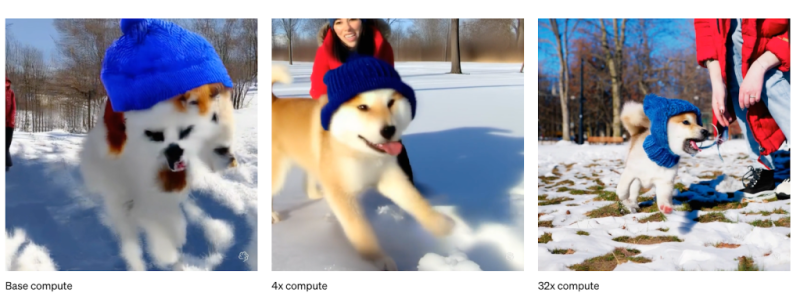
*코멘트 → 올해 2월 오픈AI AGI 자료 <오픈AI가 만든 AGI의 초석, ‘소라(Sora)’>에서도 정리해드렸었는데요. 이 모든 AI 연구의 핵심은 ‘Scalings Laws’가 유지된다는 것에 있습니다. 기업들이 스케일링 법칙을 믿고 더 좋은 AI를 얻기 위해 ‘미리 투자’하고 있는 상태이기 때문입니다.
유효컴퓨팅의 각 OOM(1 OOM = 10배)마다 예측가능하고도 안정적으로 개선되는 흐름을 보였습니다. 반대로 OOM을 계산할 수 있다면 대략적이고 정성적으로 기능이 얼마나 좋아질지를 추정할 수 있습니다. 몇몇 선견지명이 있는 사람들이 GPT-4가 출시되면 어느 정도 수준일지를 이렇게 예측했습니다.
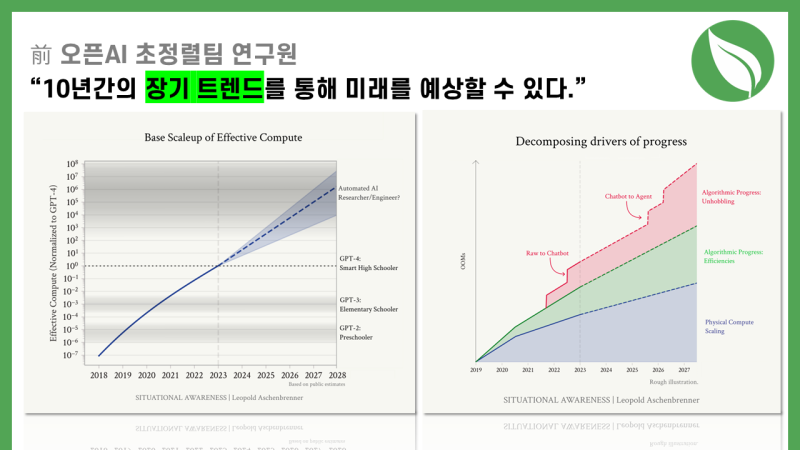
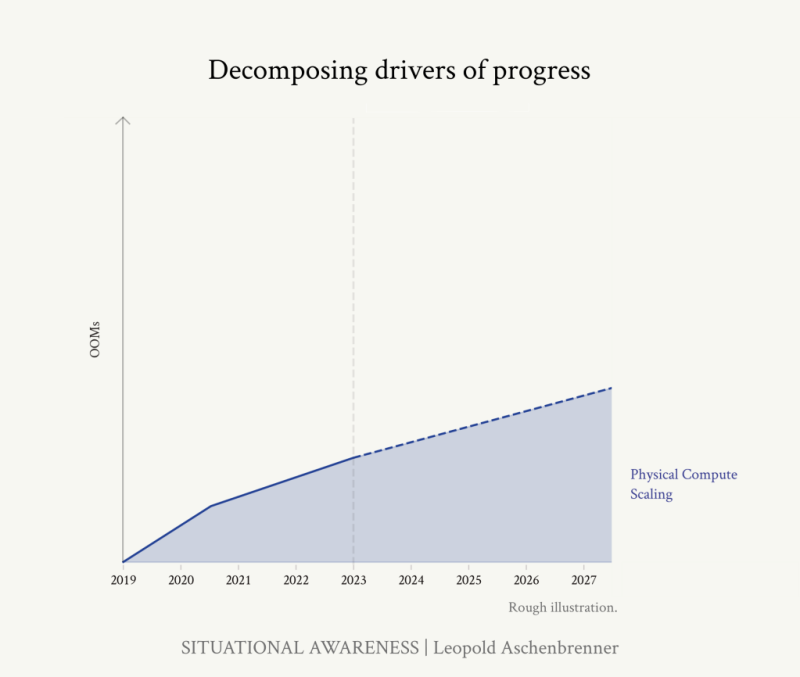
GPT-2에서 GPT-4까지의 4년간 진행 상황을 세 가지 카테고리의 발전이라고 요약할 수 있습니다.
-
-
컴퓨팅(Compute) : 훨씬 더 큰 컴퓨터를 사용하여 모델을 훈련합니다.
-
알고리즘 효율성(Algorithmic efficiencies) : 알고리즘은 지속적으로 발전하고 있습니다. 이중 다수는 단계별로 쓸 수 있는 컴퓨팅의 양이 많을 수록 좋아집니다.
-
언호블링에서 얻는 것(Unhobbling gains) : 각 모델들의 원시적인 성능은 놀랍도록 발전하지만 온갖 뒤떨어진 훈련-추론 방법으로 인해서 성능을 다 내지 못하곤 합니다. 사람들의 피드백을 통한 강화학습(RLHF)이나 생각의 사슬(CoT), 각종 도구를 쓰거나 스캐폴딩 같은 알고리즘 개선으로 상당한 잠재력을 발휘할 수 있습니다.
-
*코멘트 → ChatGPT도 GPT-3에서부터 시작한 프로젝트였습니다. 사람들로부터 피드백을 받아서 훈련시켜보면 더 좋은 데이터셋을 얻을 수 있고 성능도 좋아지지 않을까?로부터 시작된 것이었습니다. GPT-3 자체는 ‘사용자의 의도’를 파악할 수 없었거든요. 그래서 사용자의 질문의도와 일치(Aligned)하기 위해 RLHF를 도입했습니다. 이 데이터를 이용해서 파인튜닝한 데이터로 GPT-3.5(초기에는 InstructGPT)를 출시했었습니다.
이러한 축을 만들면 OOMs의 트렌드를 계산할 수 있습니다. 유효컴퓨팅 단위로 바꿔서 각각의 스케일업을 눈으로 볼 수 있다는 것입니다. 예를 들어 0.5 OOMs = 3배, 1 OOM = 10배, 1.5 OOMs = 30배, 2 OOMs = 100배를 의미합니다. 따라서 2023년 말을 기준으로 2027년까지 GPT-4에서부터 시작해서 무엇까지 기대할 수 있는지를 알아봅시다.
컴퓨팅파워
Compute
최근 가장 많이 논의되고 있는, 모델 그자체의 훈련과 추론에 더 많은 컴퓨팅을 쓰도록 하는 것에 대해서 시작하겠습니다. 많은 사람들은 이것이 단순히 무어의 법칙 때문이라고 생각합니다. 하지만 무어의 법칙이 전성기에 달할 때에도 10년 동안 1~1.5 OOM정도만 증가했습니다. 지금 생각해보면 빙하기에 가까웠습니다. 현재는 막대한 투자로 인해 무어의 법칙 5배 속도로 컴퓨팅이 빠르게 증가하고 있습니다. 단일 모델에 백만 달러(14억원)를 투자하는 건 예전에는 아무도 하지 않을 터무니 없을 일이었지만 지금은 용돈 정도입니다.
|
모델 |
요구 컴퓨팅 |
컴퓨팅 증가율 |
|
GPT-2 (2019) |
4e21 FLOP |
|
|
GPT-3 (2020) |
3e23 FLOP |
2 OOMs |
|
GPT-4 (2023) |
8e24~4e25 FLOP |
1.5~2 OOMs |
연구수준의 컴퓨팅을 사용하다가 GPT-3에서 GPT-4로 오면서는 이제 전체 데이터센터의 클러스터를 기존에 없던 규모로 키워야 하는 컴퓨팅 오버행이 크게 발생했었습니다. 다음 모델을 위해 완전히 새롭고 훨씬 더 큰 클러스터를 구축해야 하는 문제로 접어든 것입니다. 그럼에도 불구하고 드라마틱한 성장은 계속됩니다. Epoch AI 추정에 따르면 GPT-4 훈련에 쓰인 컴퓨팅은 GPT-2에 비해 약 3,000~10,000배 더 많은 양이었습니다.
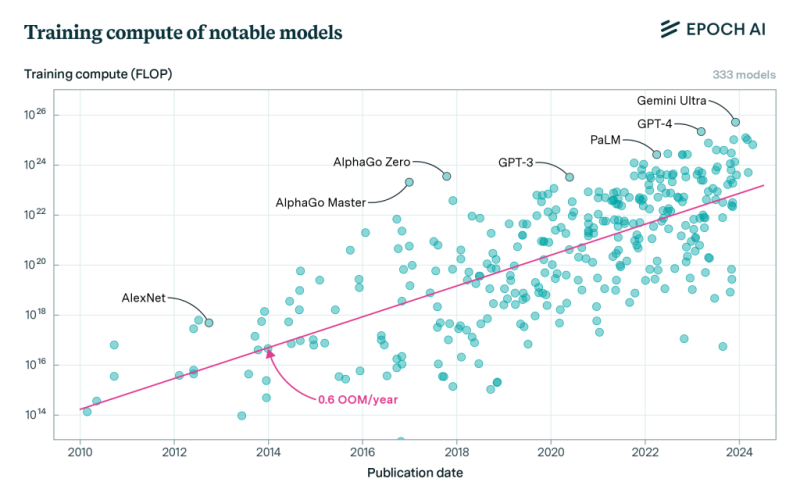
*코멘트 → 딥러닝 모델별 훈련에 쓰인 컴퓨팅 스케일, 아래 X축은 시간이고 위 Y축은 훈련 컴퓨팅 규모입니다.
그러나 크게 보면 장기적인 장기적인 추세의 연장일 뿐이었습니다. 지난 10년 반 동안 광범위하게 투자가 이뤄졌고 프론티어 AI에 사용된 훈련용 컴퓨팅은 연간 0.5 OOMs(3배) 속도로 성장해왔습니다.
모든 징후는 장기적인 추세가 계속될 거라고 말하고 있습니다. 대규모 GPU 주문에 대한 드라마틱한 이야기가 흘러나오고 있고, 이와 관련된 투자가 엄청날 것인데 현재 진행 중입니다. 이에 대해서는 향후 ‘IIIa. $1T를 향한 컴퓨팅 클러스터편‘에서 다루겠습니다. 2027년에는 2 OOMs의 컴퓨팅인 $10B 규모의 GPU 클러스터가 기본이 될 것이며 심지어는 3 OOMs에 가까운 클러스터로 $100B 규모도 그럴듯 해 보입니다. 현재 마이크로소프트와 오픈AI 및 구글이 작업 중이라는 소문이 있는 클러스터 규모입니다.
알고리즘 효율성
Algorithmic efficiencies
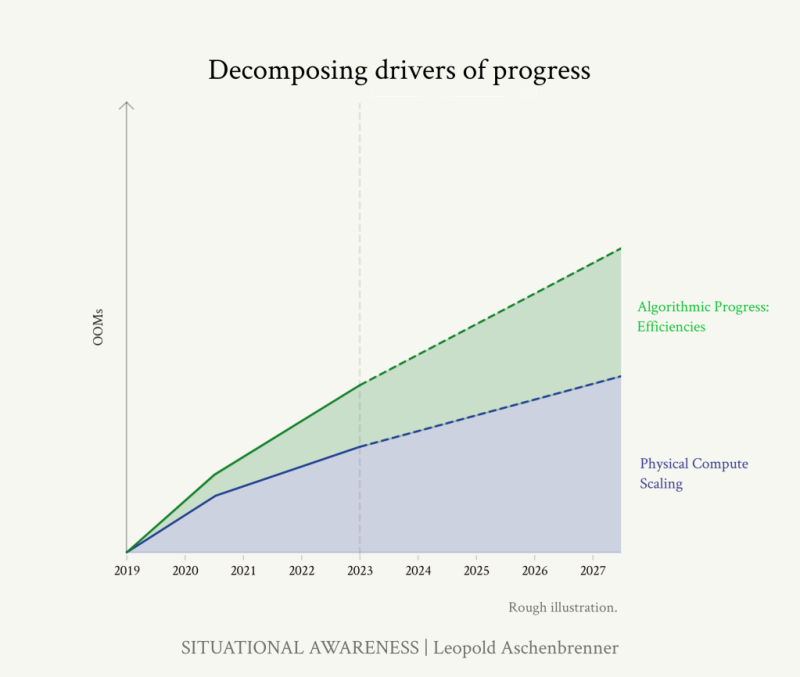
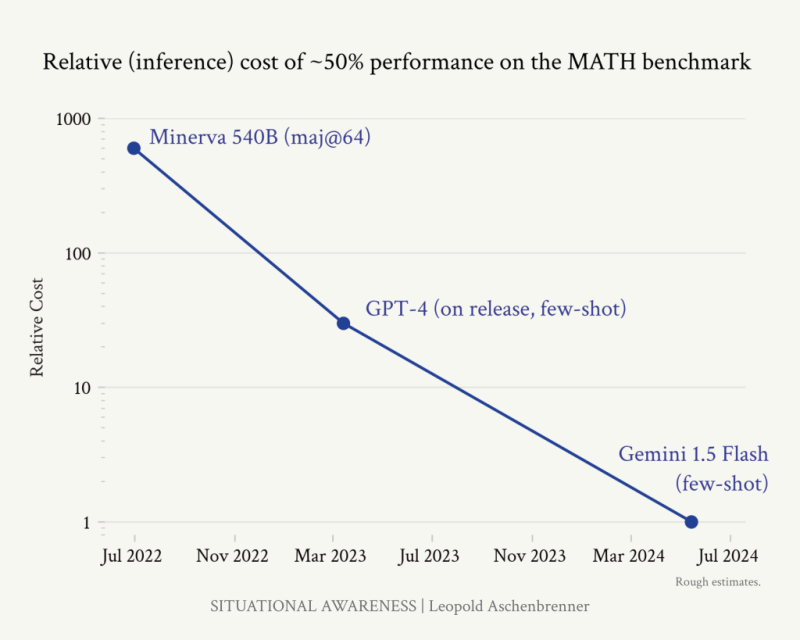
*코멘트 → 왼쪽 차트는 컴퓨팅이 증가함에 있어서 원시적인 컴퓨팅 스케일링만 있을 경우의 각도입니다. 오른쪽 차트는 MATH 벤치마크에서 정답을 50% 맞추기 위해 필요했던 추론비용은 2년도 되지 않아 1,000배 낮아진 것을 보여줍니다. 이에 대해서는 이전 <빌 게이츠, 오픈AI 샘 올트먼 인터뷰 : 40배 낮아진 GPT 비용>에서 알고리즘 효율성의 중요성을 찾아보실 수 있습니다. GPT-3는 3년 동안 비용이 40배 낮아졌고, GPT-3.5는 10배, GPT-4 비용도 계속해서 낮아지고 있다는 내용이었습니다.
컴퓨팅에 대한 대규모 투자가 모든 주목을 받고 있지만 알고리즘의 발전도 그에 못지 않게 중요한 발전동력입니다. 하지만 크게 과소평가 되고 있는 분야 중 하나입니다. 알고리즘의 발전이 얼마나 큰 영향을 미치는지 보려면, 단 2년 동안 MATH 벤치마크에서 50% 정확도를 얻기 위해 필요한 추론비용이 하락한 차트를 참고하시면 됩니다. 추론 효율성은 2년도 채 되지 않아 거의 3 OOMs(1,000배)나 좋아졌습니다.
두 가지 종류의 알고리즘 개선이 있습니다. 첫 번째는 패러다임 내 알고리즘 개선입니다. 더 나은 알고리즘을 사용하면 동일한 성능을 달성하면서도 10배 더 적은 훈련용 컴퓨팅을 요구합니다. 따라서 유효컴퓨팅이 1 OOM(10배) 증가한다고 볼 수 있습니다. 두 번째는 기본모델의 기능 잠금을 푸는 언호블링(Unhobbling)에 대한 것입니다. 이는 패러다임 확장 혹은 애플리케이션 확장으로 볼 수 있습니다.
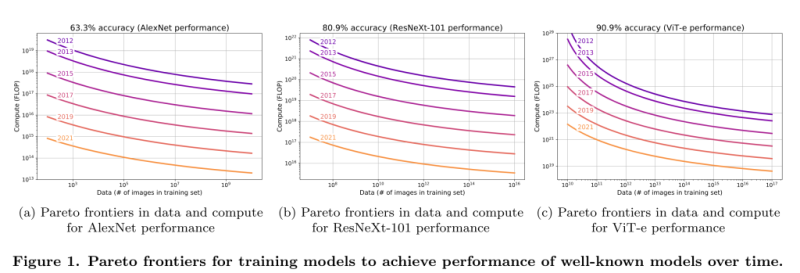
*코멘트 → 동일한 성능의 모델을 학습시키는데 있어서 2012년 대비 2021년에는 얼마나 적은 컴퓨팅을 소비하는가로 알고리즘이 매년 얼마나 컴퓨팅 효율성을 높이는가를 측정할 수 있었습니다. 이에 따라 알고리즘 효율성은 매년 0.5 OOMs의 추세를 보이고 있습니다. 매년 3배씩 성능을 좋게 만드는 요인입니다.
장기적인 추세를 보면 새로운 알고리즘으로 개선되는 추세가 상당히 일관됩니다. 분명히 개별적인 연구원들의 발견은 무작위로 이뤄지고 있고, 매번 극복할 수 없는 장애물이 있다고 다들 느끼지만, 장기적인 추세선으로 볼 때는 예측가능한 그래프를 그려오고 있습니다. 그래서 저는 추세선을 믿습니다.
2012년부터 2021년까지 9년 동안 매년 0.5 OOMs씩 꾸준히 컴퓨팅 효율성을 개선해온 이미지넷이 그 추세선을 증명하는 모델입니다. 4년 후에는 반대로 보자면 약 100배 적은 컴퓨팅으로 동일한 성능을 달성할 수 있게 된다는 의미이고, 동일한 컴퓨팅을 쓴다면 100배 더 좋은 성능을 낼 거라는 의미입니다.
모델 훈련과 추론에 드는 비용을 유추할 수 있습니다.
-
-
GPT-4는 엄청난 성능향상을 이뤘음에도 불구하고 출시 당시 비용은 GPT-3와 거의 같았습니다.
-
1년 전 GPT-4가 출시된 이후 GPT-4o가 출시될 때에는 이미 이전에 비해 낮았던 GPT-4 모델 API 가격이 입력은 6배, 출력은 4배 더 하락했습니다.
-
최근 출시된 제미나이 1.5 Flash는 기존 GPT-4보다 입력은 85배, 출력은 57배 더 저렴한 비용으로 GPT-4에 약간 못미치는 수준(GPT-3.75?)의 성능을 제공합니다. 이제 엄청난 효율이 나오고 있습니다.
-
제미나이 1.5 Pro는 훨씬 더 컴퓨팅을 사용하면서 제미나이 1.0 울트라 성능을 능가했으며, 그 과정에서 새로운 아키텍처인 MoE를 사용했습니다. 여러 논문을 봐도 MoE의 컴퓨팅 효율화 능력은 상당합니다.
-
언호블링
Unhobbling
마지막은 정량화하기 가장 어렵지만 그에 못지 않게 중요한 개선요소인 ‘언호블링’입니다. *호블링은 일종의 절름발이 상태를 의미합니다. 언호블링은 따라서 제대로 걷게 해주는 것, 고쳐주는 것*을 의미한다고 해석할 수 있습니다.* 어려운 수학문제를 풀라고 LLM에게 요청할 경우 처음에는 잘 해결하지 못했습니다. 그러나 생각을 줄이어 하도록 하는 CoT 프롬프트를 적용함으로써 LLM은 수학문제를 잘 풀고 있습니다. 각 애플리케이션에 맞는 알고리즘을 약간만 수정시켜줌으로써 훨씬 더 좋은 성능을 낼 수 있게 해주는 일입니다. 이미 몇 년 동안 모델을 추론함에 있어서 언호블링 사례를 충분히 많이 봤습니다. RLHF, CoT, Scaffolding, Tools, Context Length, Posttraining improvements 등 많은 사례가 있습니다.
일반적으로 이러한 기법들은 벤치마크에 따라 다르지만 5~30배 더 효과적인 컴퓨팅 효율을 가져옵니다. 컴퓨팅은 더 적게 쓰고 성능도 좋아지는 게 가능합니다.
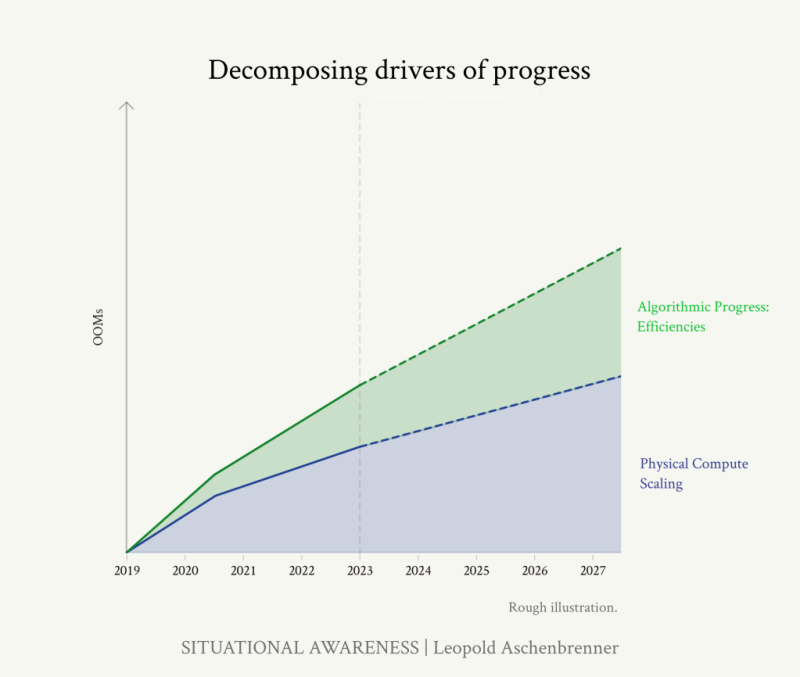
수많은 모델들을 더 유용하게 만들고 있으며, 오늘날 많은 상용 애플리케이션 적용을 발목잡고 있는 것은 생각보다 호블링 때문이라고 주장하고 싶습니다. 현재 모델들은 엄청나게 많은 제약을 겪고 있습니다.
-
-
모델들은 장기 기억을 하는 기능이 없습니다.
-
모델들이 컴퓨팅 양을 마음대로 조절할 수 없습니다. 도구도 매우 제한적입니다.
-
모델들은 사람이 말하기 전에 생각하지 않습니다.
-
모델들은 하루 혹은 일주일 동안 문제에 대해서 오랫동안 생각하고, 다양한 접근방식에 대해서 생각해보고, 다른 사람과 상담하고, 더 긴 보고서를 읽거나 하지 않습니다. 짧은 대화만 가능합니다.
-
모델들은 당신과 당신의 소프트웨어와 소통하고 있지 않습니다. 업무에 관련된 배경지식, 회사와 관련된 배경지식이 있는 것이 아니라 짧은 프롬프트만 받아서 수행하는 챗봇일 뿐입니다.
-
이를 해결하기 위한 생각
-
온보딩 문제 해결 : 지금 GPT-4는 마치 많은 사람들의 직업을 상당부분 대체할 수 있는 능력을 이미 가졌지만, 5분 전에 업무에 뛰어든 똑똑한 신입사원과도 같습니다. 관련된 맥락 정보를 전혀 모르고 회사 문서를 넣지도 않았습니다. 아무리 똑똑한 신입사원이라 해도 입사 5분이 지나자마자는 그다지 유용할 수 없습니다. 하지만 한 달 후에는 꽤 유용합니다.
-
장기간 추론하고 스스로 오류를 수정하는 시스템 : 지금 모델은 짧은 작업만 수행할 수 있습니다. 물으면 바로 답합니다. 하지만 인간이 하는 대부분의 작업 그리고 가장 가치가 높은 작업들은 더 긴 시간동안 생각해야 합니다. 5분이 아니라 몇 시간, 며칠, 몇 주 또는 몇 달이 걸리는 작업입니다. 만약 인간의 역사에서 어려운 문제를 주고 5분 안에만 풀라고 했다면 어떠한 과학적인 발견도 없었을 겁니다. 그러나 문제는 기본적으로 상당히 많은 컴퓨팅을 필요로 합니다. 문제를 생각할 때 내부적으로 토큰을 쓸 것이기 때문입니다. 어려운 문제가 더 장기 프로젝트를 생각할 때 더 많은 토큰, 수백만 개, 수천, 수억 개의 토큰을 사용할 수 있게 해준다면 어떨까요? 몇 분을 생각한 것과 몇 달을 생각한 것의 질은 다르고 할 수 있는 일도 훨씬 더 많아질 겁니다.
|
토큰 수 |
컴퓨팅의 최대 시간 |
컴퓨팅 증가율 |
|
100초 |
몇 분 |
ChatGPT의 현재 상태 |
|
1,000초 |
30분 |
+ 1 OOM |
|
10,000초 |
4시간 |
+ 2 OOMs |
|
100,000초 |
일주일 |
+ 3 OOMs |
|
1,000,000초 |
몇 개월 |
+ 4 OOMs |
*코멘트 → 인간의 생각이 분당 최대 100토큰을 쓴다고 하고, 주당 40시간 일한다고 가정하면 모델이 생각하는 시간을 토큰으로 바꿔서 생각할 수 있습니다. 이를 한 문제 혹은 하나의 프로젝트에 할당할 시 더 높은 사고가 가능해질 겁니다.
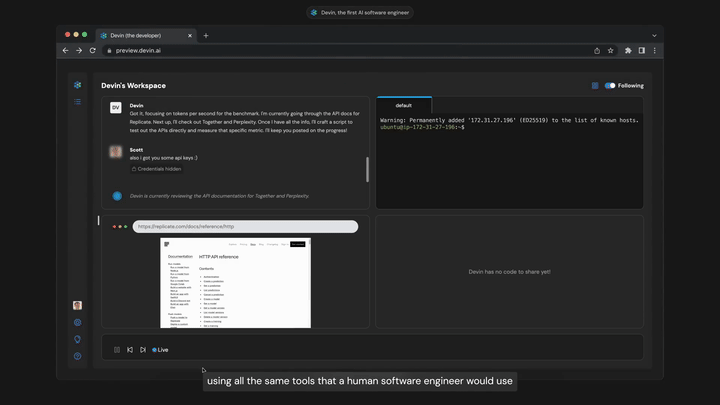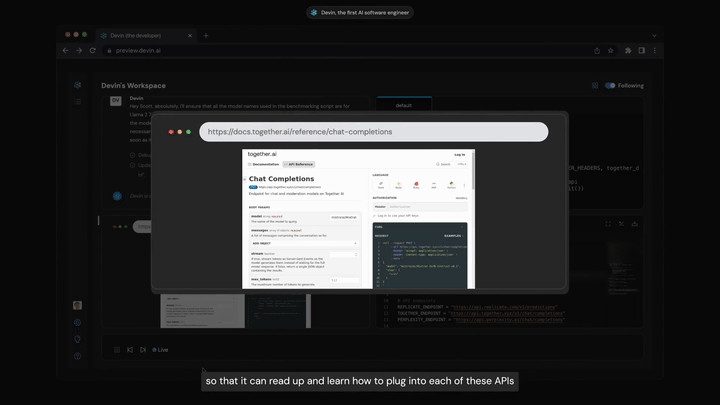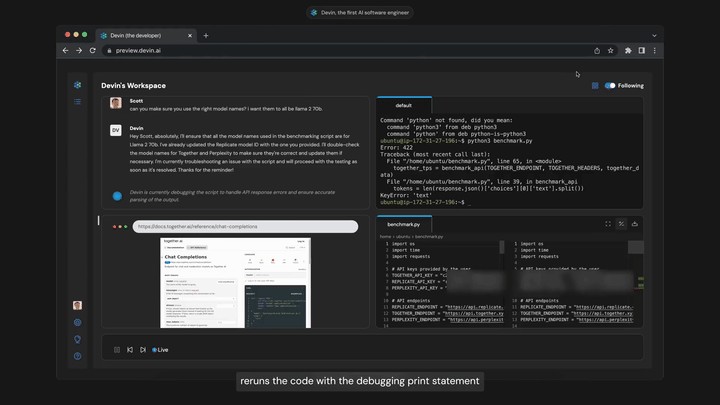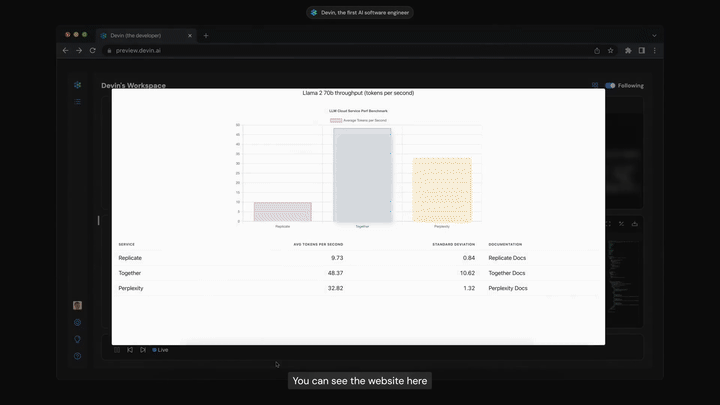
*코멘트 → 소프트웨어 엔지니어가 하는 일 자체를 자동화한 AI ‘데빈(Devin)’이 실행되는 모습입니다. 얼마나 잘 작동할지는 아직 부족하지만 챗봇이 아니라 독립적인 개체로서 일하게 하는 중요한 발전이었습니다. 새로운 코드를 학습하거나 GitHub에 코드 버그가 뜨면 ‘알아서’ 고치는 방법을 구글에 검색해서 찾은 뒤 디버깅해보고 코드에 적는 식입니다.
-
모델이 스스로 컴퓨팅을 쓰는 것 : 현재 ChatGPT는 문자메시지만 주고받는 격리된 사람과도 같습니다. 이 과정에서 나아가려면 멀티모달모델에서 가능해집니다. 사람처럼 스스로 Zoom 미팅에 참석도 하고, 온라인으로 구글링하고, 사람들에게 메시지를 보내고, 이메일을 보내고, 문서를 읽고, 앱을 만드는 식입니다. 마치 집에서 일하는 재택근무자처럼 행동하는 것입니다. 데빈은 장기적인 추론과 계획 능력을 갖춘 좋은 사례였습니다. 작업 과정의 모든 활동을 기억하고 학습하며 오류도 스스로 분석하고 수정하는 모델이기 때문입니다. 오류는 줄어갈 것이며 이로 인해 창출될 경제적 가치는 불연속적으로 증가할 수 있습니다. 0에서 어느 순간 1이 되는 것입니다.
향후 4년
The next four years


지금까지의 수치를 종합하면 2027년 말까지 GPT-4 이후 4년 동안 GPT-2 → GPT-4에서 이룬 도약 만큼을 다시 한 번 이룰 것으로 예상할 수 있습니다. GPT-2 → GPT-4로 전환할 때는 대략 4.5~6 OOMs의 유효컴퓨팅 증가(실제 컴퓨팅 증가*알고리즘 효율*언호블링)가 있었습니다. 향후 4년 동안은 컴퓨팅에서 2~3 OOMs * 알고리즘 효율성에서 1~3 OOMs로 최대 5 OOMs 성능개선이 이뤄지며, 언호블링으로 더 많은 업무에 쓰일 거라 예상합니다.
바꿔서 생각해보면, 이전 GPT-4 훈련에 3개월이 걸렸다고 가정하면 2027년에는 세계 최고 수준의 AI 연구소에서는 1분 만에 GPT-4 수준의 모델을 훈련할 수 있게 된다는 뜻입니다. 드라마틱한 개선이 이뤄집니다.
앞으로 어떻게 될까요?
Where will that take us?
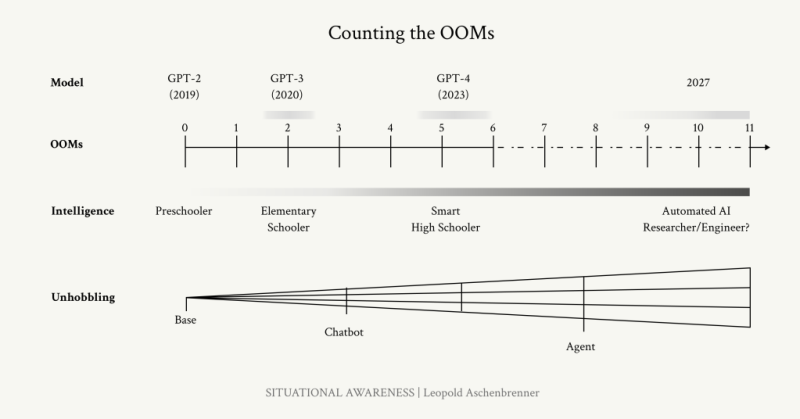
미취학 아동에서 스마트폰 고등학생으로, 문장을 몇 개 엮던 수준에서 고등학교 시험을 치르고 코딩 코파일럿 역할을 하는 수준으로 올라왔습니다. 엄청난 도약이었습니다. 이제 다시 한 번 현 수준에서 지능도약이 이뤄질 것입니다. 우리는 어디까지 도달할 수 있을까요? 아주 먼 곳까지 갈 수 있다 해도 놀라지 않아야 합니다. 아마 한 분야의 박사나 최고 전문가를 능가하는 모델은 등장할 수 있을 것입니다.
현 AI 발전 추세는 아동발달 속도의 3배 수준이라 생각하면 직관적입니다. 당신이 1살씩 먹을 때마다 이제 막 고등학교를 졸업한 자녀는 3살씩 먹고 있습니다. 어느 순간 직업을 대체할 것입니다. 다시 한 번 강조하지만, 믿을 수 없을 정도로 똑똑한 ChatGPT를 상상하는 것이 아닙니다. 추론하고 계획하며 오류를 스스로 수정하고, 여러분과 여러분의 회사에 대해 모든 것을 알고 있으며 몇 주 동안 독립적으로 문제를 해결할 수 있는 재택근무자처럼 보일 것입니다.
우리는 2027년까지 AGI를 향해 나아가고 있습니다. AI 시스템은 근본적으로 우리의 모든 인지적 작업(원격으로 수행할 수 있는 모든 일)을 자동화시키는 데 초점을 맞추고 있습니다. 분명한 것은 오차범위가 크다는 것입니다. 데이터의 벽, 알고리즘의 혁신, 호블링을 해제하는 것, 딥러닝의 추세선이 깨질 수도 있습니다.
어쨌든 우리는 OOMs를 통해서 AGI를 향해 가는 길을 예상할 수 있습니다. 2027년까지 진정한 AGI의 가능성이 온다는 것을 진지하게 받아들이기 위해서는 단지 추세선을 믿는 것만으로는 부족합니다.
요즘 많은 사람들이 AGI를 평가절하하는 게임에 빠져 있는 거 같습니다. AGI는 저나 제 친구들이 하는 일처럼 AI를 다루는 연구나 엔지니어 업무를 완전히 자동화 할 수 있는 AI 시스템을 말하는 것입니다. 의료나 법률은 사회적 선택이나 규제로 인해 도입이 늦어질 수도 있습니다. 그러나 모델이 스스로 AI 연구를 할 수 있게 된다면 그것만으로 강력한 피드백 루프가 열립니다. 자동화된 AI 엔지니어는 모든 병목을 해결하여 진전할 것이라 생각합니다. 가능성과 무관하게 수백만 명의 연구원들이 10년 동안의 알고리즘 발전을 1년 내로 압축시킬 수 있는 가능성에 대해서도 생각해봐야 합니다. 그럼에도 불구하고 AGI는 그 후 곧 다가올 초지능(Superintelligence)에 비하면 맛보기일 뿐입니다.
어떠한 경우든, 가파른 상승세가 꺾일 거라 기대하지는 마세요. 추세선은 단기적으로 순진한 믿음 같지만 그 함의는 강력했습니다. 이전 모든 세대원들이 그렇게 생각했던 것처럼, 새로운 세대의 모델은 세상을 다시 한 번 어리둥절하게 만들 것입니다. 조만간 박사 학위가 필요한 엄청나게 어려운 과학 문제를 AI가 해결할 수 있고, 컴퓨터로 스스로 업무를 처리하고, 수백만 줄의 코드를 처음부터 다시 작성할 수 있게 됩니다. 이러한 모델이 창출하는 경제적 가치가 매년 10배씩 증가한다고 한다면 놀랄 겁니다. SF 소설같지만 OOMs를 세어보세요. AGI는 더 이상 먼 미래의 공상과학소설이 아닙니다.
딥러닝 기술의 확장은 이제 막 성공했고, 모델은 여전히 학습하고 싶어하며, 2027년 말까지 100,000배 이상의 컴퓨팅 증가가 있을 것입니다. 머지않아 우리보다 더 똑똑해질 것입니다.
GPT-4는 시작에 불과합니다. 4년 뒤 우리는 어디에 있을까요?
GPT-4 is just the beginningㅡwhere will we be four years later?

다음 편에서 이어집니다
*호흡이 길기에 시차를 두고 나올 예정입니다*
함께 읽으시면 좋은 글
|
AI 업계를 이해하는 자료 |
|
|
2024-02-21 |
구글 잼민이 왜케 잘해, ‘제미나이(Gemini) 1.5’ (바로가기) |
|
2024-02-20 |
오픈AI가 만든 AGI의 초석, ‘소라(Sora)’ (바로가기) |
|
2023-12-27 |
엔비디아와 생성형AI : ‘Zero to One’ 첫 해를 정리하며 (바로가기) |
|
오픈AI 인터뷰 |
|
|
2024-03-26 |
오픈AI 샘 올트먼 인터뷰 : “컴퓨팅은 세계에서 가장 귀중한 화폐가 될 것” (바로가기) |
|
2024-01-19 |
빌 게이츠, 오픈AI 샘 올트먼 인터뷰 : 40배 낮아진 GPT 비용, 지능 → 로봇 생산성 혁신 (바로가기) |
|
2024-01-12 |
|



